Architecture Overview
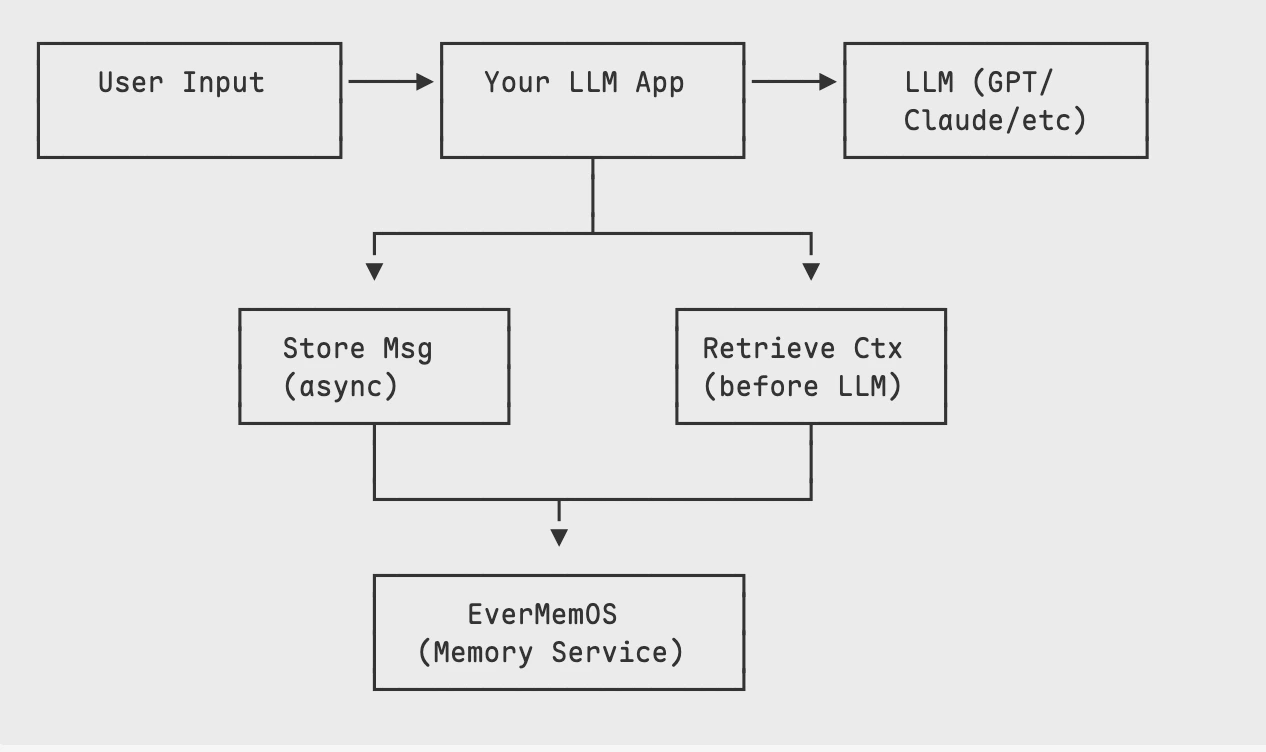
- Stores every conversation turn in EverOS
- Retrieves relevant context before generating responses
- Uses the context to personalize LLM responses
Setup: Install the SDK
Install the EverOS Python SDK and initialize the client. No scene or conversation-meta configuration is needed in v1 — just start adding memories directly.Store Conversation Messages
Store each conversation turn asynchronously. EverOS processes them in the background.Retrieve Relevant Context
Before generating a response, retrieve relevant memories to provide context to your LLM.Complete Assistant Loop
Here’s a complete implementation that ties everything together:Example: Using Preferences
After a few conversations, your assistant can leverage stored preferences:Best Practices
Context Window Management
Context Window Management
Limit retrieved memories to avoid overwhelming your LLM context window.
Choose the Right Search Method
Choose the Right Search Method
EverOS v1 supports multiple search methods. Pick the one that fits your use case.
Filter by Memory Type
Filter by Memory Type
Request only the memory types you need to keep results focused.
Next Steps
Search Methods
Deep dive into vector, hybrid, and agentic retrieval
Python Integration
Production-ready async patterns and error handling