EverOS Cognitive Loop
Memory Construction
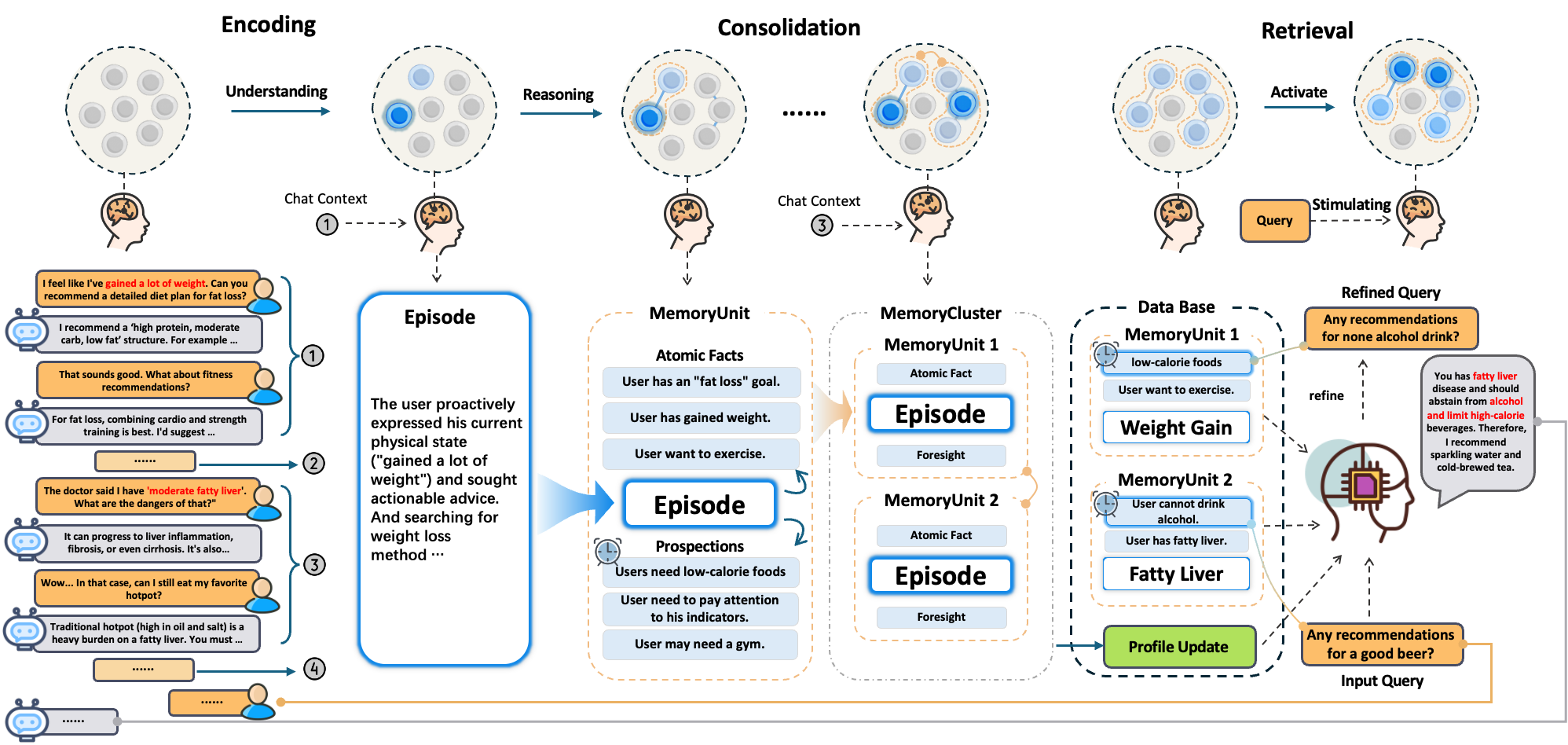
This track turns raw conversation streams into structured, retrievable knowledge.1
Ingestion
Raw messages enter the system through the API. Multi-modal content (images, PDFs, audio, HTML) is parsed and normalized alongside text.
2
Boundary Detection
The system identifies shifts in topics or context to segment the conversation into meaningful units.
3
Extraction
Specialized prompts and models extract MemCells — the atomic memory units: Episodes, Atomic Facts, Foresight, and Profile updates.
4
Consolidation
MemCells are integrated by theme and participants to form episodes and profiles.
5
Indexing
Data is stored with both keyword (BM25) and semantic (vector) indices for robust retrieval.
md_change_state queue and replay on recovery. LanceDB unavailability never blocks a write response.
Memory Perception
This track handles how agents retrieve and use stored memories. Four methods are available, each with different performance and dependency trade-offs:keyword: BM25 full-text search — fast, exact term matching, no model dependenciesvector: ANN embedding similarity — semantic queries, requires an embedding modelhybrid(recommended): BM25 + vector in parallel, hierarchical fusion where atomic facts and episodes compete for the top-N results, followed by LLM rerank — best recall and precisionagentic: Multi-round adaptive retrieval — LLM checks sufficiency and generates follow-up queries if needed
The EverAlgo Boundary
Memory extraction algorithms live in a separate library, EverAlgo, not in EverOS itself. It handles:- Multi-modal parsing (text, image, audio, doc, PDF, HTML, email)
- Episode / AtomicFact / Foresight / Profile extractors
- Case / Skill extractors for agent memory
PromptSlot parameters rather than hardcoded, so every extraction stage is configurable without touching algorithm code.